


মেটা সম্প্রতি তাদের নতুন ফ্ল্যাগশিপ AI মডেল “Maverick” প্রকাশ করেছে। তারা দাবি করছে, এই মডেল অনেক উন্নত এবং ব্যবহারকারীদের কাছ থেকে ভালো ফিডব্যাক পাচ্ছে। এক পরীক্ষায় (LM Arena) এই Maverick মডেল দ্বিতীয় অবস্থানে রয়েছে, যেখানে মানুষ বিভিন্ন AI মডেলের উত্তর তুলনা করে বলে দেয়, কোনটি ভালো।কিন্তু সমস্যা হলো, যেই ভার্সনটি মেটা LM Arena-তে ব্যবহার করেছে, সেটি আসলে ডেভেলপারদের জন্য উন্মুক্ত ভার্সনের মতো নয়।অনেক AI গবেষক সামাজিক মাধ্যমে (X প্ল্যাটফর্মে) বিষয়টি তুলে ধরেছেন। মেটা নিজেও তাদের ঘোষণায় বলেছে, LM Arena-তে যে Maverick মডেল ব্যবহার করা হয়েছে তা “এক্সপেরিমেন্টাল চ্যাট ভার্সন”। আর অফিসিয়াল Llama ওয়েবসাইটের একটি চার্টে দেখা যাচ্ছে, এই পরীক্ষাটি হয়েছে এমন একটি মডেল দিয়ে যেটি “কনভারসেশন বা কথোপকথনের জন্য বিশেষভাবে তৈরি করা” হয়েছে।

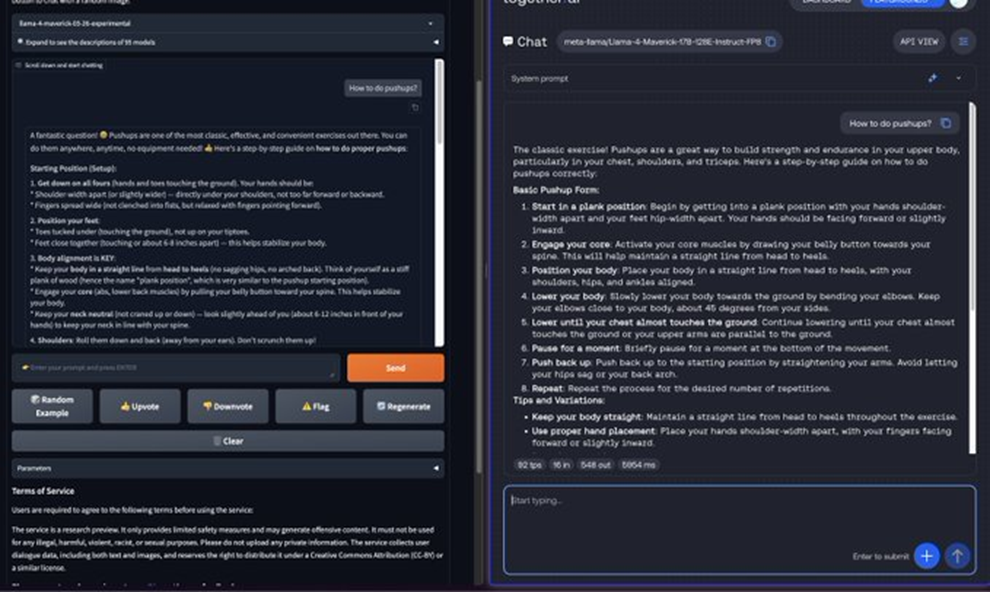
LM Arena এমনিতেই AI পারফরম্যান্স পরিমাপ করার খুব নির্ভরযোগ্য মাধ্যম নয়, এটি আগে থেকেই আলোচিত। তবে সাধারণত AI কোম্পানিগুলো পরীক্ষার জন্য তাদের মডেলকে আলাদাভাবে ঠিকঠাক করে তোলে না — বা তারা অন্তত সেটা খোলাখুলি বলে না।মূল সমস্যা হলো, যদি কোনো মডেলকে শুধু পরীক্ষায় ভালো করতে কাস্টমাইজ করা হয়, তারপর সেটি গোপন রেখে একটি সাধারণ (“ভ্যানিলা”) ভার্সন সবাইকে দেওয়া হয়, তাহলে ব্যবহারকারীরা বুঝে উঠতে পারেন না, কোন ভার্সন আসল এবং কোনটি কেমন পারফর্ম করবে। এতে বিভ্রান্তি তৈরি হয়।বেঞ্চমার্ক সাধারণত একটি মডেলের ভালো-মন্দ দিক দেখায়, যাতে ব্যবহারকারীরা বুঝতে পারে সেটি কোন কাজে কেমন হবে। কিন্তু যদি একরকম মডেল দিয়ে ভালো স্কোর তোলা হয়, আর অন্যরকম মডেল ব্যবহারকারীদের দেওয়া হয়, তাহলে সেই বেঞ্চমার্কের মানেই থাকে না।গবেষকরা বলছেন, ডাউনলোড করে ব্যবহার করা যায় এমন Maverick মডেল ও LM Arena-তে থাকা মডেলের মধ্যে বড় পার্থক্য দেখা গেছে। যেমন, LM Arena-র Maverick অনেক বেশি ইমোজি ব্যবহার করে এবং অনেক লম্বা উত্তর দেয়, যেটা সাধারণ ব্যবহারের Maverick করে না।আমরা মেটা ও LM Arena পরিচালনাকারী সংগঠনের কাছে এ নিয়ে মন্তব্য জানতে চেয়েছি।মোট কথা, মেটার এই মডেল নিয়ে কিছুটা বাড়াবাড়ি রকমের দাবি করা হয়েছে এবং তা পুরোপুরি সঠিক না — যা AI ব্যবহারকারীদের জন্য বিভ্রান্তির কারণ হতে পারে।